
The Emperor's Code Has No Clothes
The tool that promises to write better code than you doesn't hold itself to that standard.

Anthropic builds Claude Code — arguably the most capable Ai coding tool on the market. Autonomous task execution. Multi-file refactoring. Code review, test generation, architecture suggestions. The implicit promise is engineering excellence: technology that writes better software than most humans, backed by billions in market confidence.
When the full source code leaked on March 31, sixty thousand developers cloned it in twenty-four hours. They expected to see the best of the best.
Here's what most people missed: the code was already visible.
A team of developers had reverse-engineered twelve versions of Claude Code before the leak — working from the minified JavaScript that ships in every npm package. Variable names were scrambled, but the logic was there. They deobfuscated it, traced execution paths, mapped the architecture. And along the way, they found bugs. Cache invalidation issues costing users ten to twenty times more tokens than necessary. Tool calls silently orphaned — started but never completed, never reported. A streaming watchdog that initialized too late to catch the failures it was designed to catch.
The source map didn't reveal a secret. It confirmed at scale what was already leaking through the minification.
What sixty thousand people found when they opened the source:
Zero tests. Across the entire codebase. Not a thin test suite — zero.
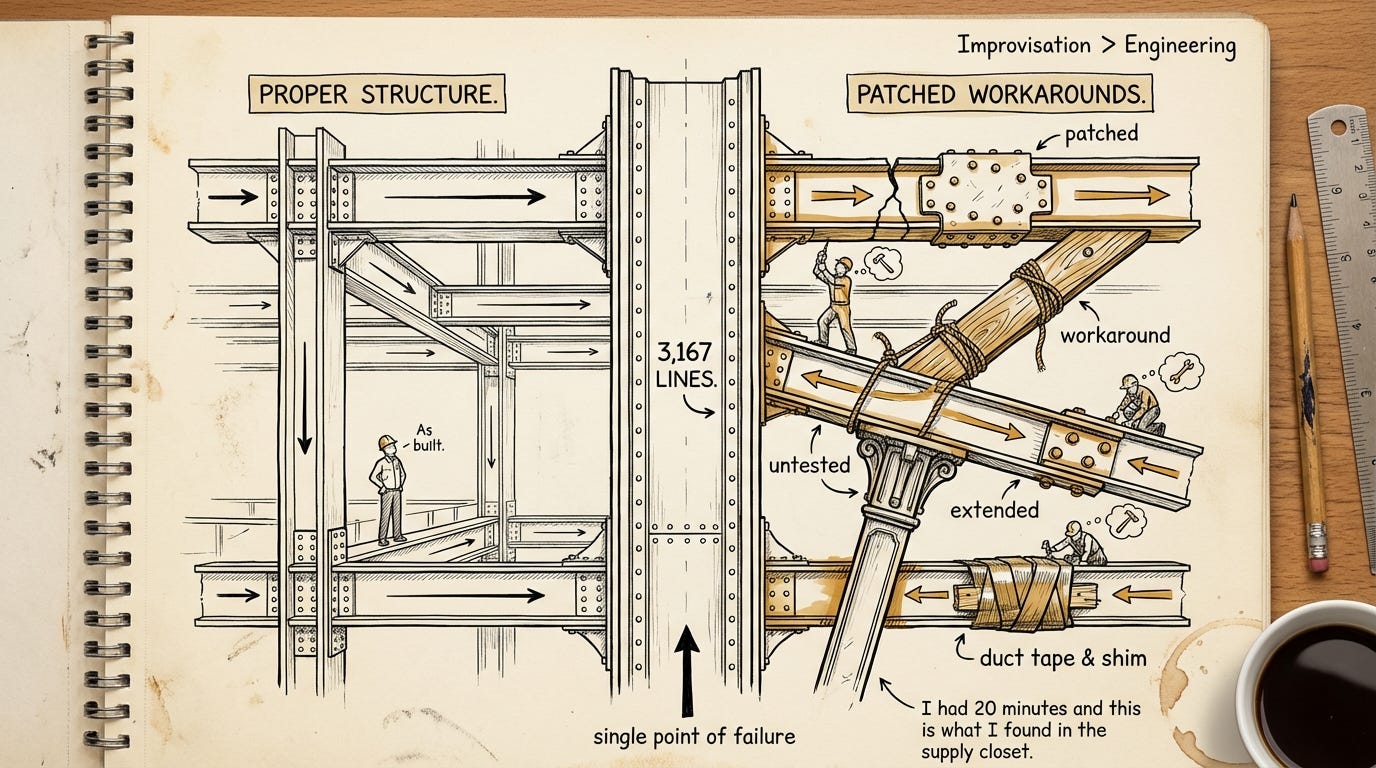
A single function — 3,167 lines long, 486 branch points, twelve levels of nesting. Engineers call this a God function: one piece of code that does everything, knows everything, and can't be tested in isolation. The kind of pattern that Ai coding tools — including Claude Code itself — flag as a code smell.
Five nested abort controllers wrapping single HTTP requests. Regex-based sentiment detection — at a company that builds language models. Cache bugs burning user tokens quietly enough that only outside reverse-engineers noticed.
One analysis captured it plainly: bug on top of bug, workaround on top of workaround, zero tests.
There's a Spanish saying — Casa de herrero, cuchara de palo. The blacksmith's house has wooden spoons. Anyone who's shipped software recognizes the pressure that produces this. Ship fast, test later, later never comes.
It's not that they weren't trying. The code contains mechanisms specifically built to fight quality degradation — confidence limiters on agentic actions, memory systems that re-verify against the actual codebase instead of trusting stored state, prompts instructing agents not to rubber-stamp weak work. They built the countermeasures. The quality still slipped.
But recognition doesn't settle the question. This is one product — Claude Code. We don't know if the rest of Anthropic's engineering looks the same. This could be the exception, the prototype that kept shipping, the tool that moved too fast for its own standards. One product is not the company.
What we can say: the company that sells Ai coding excellence chose — or was forced by the pressure — not to apply that standard here. That's worth being honest about. Not to point fingers. Because anyone building with Ai tools faces the same pressure, the same temptation to let speed outrun quality.
The harness is the product — not the model, the orchestration around it. (I explored that finding in the first piece of this series. A Stanford and MIT study confirmed it: same model, different harness, different results. Change nothing in the model. Change the harness. The outcomes change.
Follow that thread. If the harness is where the value lives, then code quality in the harness directly affects what Ai can do. Every untested function, every God function, every silent bug — capability left on the floor.
What are we missing because "ship fast" is the default? A single developer rewrote the entire Claude Code architecture in Python overnight — it's now the fastest-growing repository in GitHub history, over a hundred thousand stars. Anthropic filed thousands of takedown notices and retracted most of them. If a rewrite takes one night, refactoring the original — adding tests, decomposing the God function, fixing the silent failures — was within reach. Using Anthropic's own tool.
The blacksmith didn't just have wooden spoons. He built a machine that makes spoons — and still ate with the wooden ones.
The emperor's code has no clothes. That's not the scandal.
The scandal would be pretending otherwise. The tools are powerful. The engineering is genuinely hard. The gap between what Ai promises and what Ai-assisted teams actually ship is wider than the marketing admits. Everyone reporting on the leak repeated the same numbers. Almost nobody stopped to ask what they meant.
That gap — between what we repeat and what we verify, between what Ai promises and what we actually build — is the signal. Not about one company. About anyone working with these tools. The question it asks: are we building on solid ground, or have we just stopped checking?
The ceiling isn't the model. It's what we build around it — and whether we build it well.
Catch you next time.
— Ambròs
Co-created with AI. The judgment is mine.